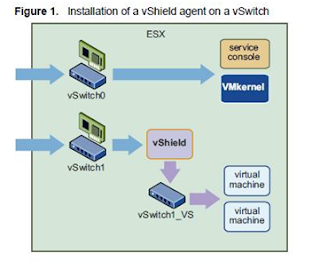
vShield Zones: An application layer firewall to protect VMs. Deployment is based on manager and agents VMs hat sits between VMs and vSwitch as shown in the diagram below.
Some of the things you should know about vShield Zones:
You will need to download vShield Manager OVF – Open Virtual Format and one vShield agent OVF templates.
VMware Wall (firewall) does application-aware traffic analysis and stateful firewall protection by inspecting network traffic and determining access based on a set of rules between unprotected and protected zones.
You can install a vShield agent on any vSwitch that homes a physical NIC.
3 Port Groups are created namely, VSprot_vShield-name, VSmgmt_vShield-name, and VSunprot_vShield-name.
40,000 concurrent sessions can be processed.
vShield Zone cannot protect the Service Console or VMkernel components
VMware Fault Tolerance or FT is a new HA solution from VMware for VMs. It is only available in vSphere 4 and above and provides much more resilient failover solution than VMware HA. One of the nice things about FT is that a VM does not need to be restarted. However, before you can start using FT for your important VMs like Domain Controllers and others here is what you need to know about Fault Tolerance?
Similar to VMware HA, Fault Tolerance (FT) provides failover capabilities at the host level failure. So it will fail over VMs only when host in the cluster fails. It does not work across clusters or datacenters.
FT uses vLockstep technology. vLockstep technology is the process of recording and replaying x86 instructions from Primary copy of the VM to Secondary VM. vLockstep also keeps track of the heartbeat between primary and secondary VMs.
While vCenter or virtual center is required to configure FT. It doesn’t have to be ON during a failure event.
You can have On-Demand Fault Tolerance for a VM.
FT makes sure that both primary and secondary VMs are on the same host using host anti-affinity check.
Following requirements must be met for VMs before FT can be configured:
Host must have certificate checking enabled
FT is enabled per VM vmdks must be thick provisioned All hosts must be from the same compatible process groups which support FT No Snapshots: A VM participating in FT cannot have any snapshots No Storage VMotion: A VM participating in FT cannot use Storage VMotion No DRS: A VM participating in FT cannot use DRS No SMP: A VM in FT can only have single vCPU No RDMs: A VM in FT cannot have RDMs but it can have vRDMs Hot-add/hot-plug is not compatible with VMware Fault Tolerance
Upon a host failure a new Secondary VM is automatically re-spawned
VMware HA must be on turned on in the cluster before FT can be enabled
Host Monitoring in VMware HA is required for FT recovery process to work properly.
FT Networking: You must have 2 different vSwitches, one for FT Logging and second for VMotion on different subnets or VLANs. It’s recommended to use 10Gb network for FT Logging traffic along with Jumbo Frames.
FT Maximums: You should not have more than 4 FT VMs per host which includes both Primary and Secondary VMs. A max of 16 vmdks per VM is allowed.
NIC pass-through is allowed
In conclusion, while FT is a very cool feature of vSphere. It does put some restrictions which are hard to meet as many IT shops would prefer to use many of the features along with FT which are not compatible with FT. And the fact that it doesn’t work across datacenters or clusters actually is not helpful since many companies these days would like to use it for their DR solutions.
VMware HA
HA is the ability of VMware to power on VMs on another ESX host in case one or more hosts fail in a cluster. Some of the things that you need to know about VMware HA are:
- HA Calculations: HA is based on what is called a “slot”. A slot is basically a reserved space for running a VM in the cluster. Two features that determine a slot are CPU and RAM used by VM. By default VMware HA selects the slot size to be the largest chunk of CPU and RAM used by a VM as shown in the diagram below. HA uses this to determine the number of slots available in the cluster to run the VMs in an HA event. The default selection can be changed by modifying the following advanced attributes: das.slotMemInMB – Change the memory usage by a VM for slot calculations das.slotCpuInMHz – Change CPU usage by a VM for slot calculations
- First 5 hosts in a cluster are designated as Primary for HA. At least 1 node in the cluster is selected as Active Primary. - HA agent is installed on the ESX host and polls for heartbeat every second by default. Failure is detected if no heartbeat is received in 15-seconds Isolation Network is polled every 12 seconds after which host is designated as Isolated. Service Console default gateway for ESX and VMkernel default gateway for ESXi are pinged for detecting isolation. You can also designate other addresses by modifying das.isolationaddress include other destination in the detection process. - Admission Control Policy: Ability to reserve resources for HA. You can use Host, VM Restart Priority to control admission policy. VM Restart priorities are defined as High – First to start. Use for database servers that will provide data for applications. Medium – Start second. Application servers that consume data in the database and provide results on web pages. Low – Start Last Web servers that receive user requests, pass queries to application servers, and return results to users. Disables admission control: If you select this option, virtual machines can, for example, be powered on even if that causes insufficient failover capacity. When this is done, no warnings are presented, and the cluster does not turn red. If a cluster has insufficient failover capacity, VMware HA can still perform failovers and it uses the VM Restart Priority setting to determine which virtual machines to power on first. - Enable port fast (Cisco) on the switches as best practice for bypassing spanning tree delays. - VM Monitoring – HA also has the ability to monitor VMs but requires that VMware Tools be installed and running. Occasionally, virtual machines that are still functioning properly stop sending heartbeats. To avoid unnecessarily resetting such virtual machines, the VM Monitoring service also monitors a virtual machine's I/O activity. If no heartbeats are received within the failure interval, the I/O stats interval (a cluster-level attribute) is checked. The I/O stats interval determines if any disk or network activity has occurred for the virtual machine during the previous two minutes (120 seconds). If not, the virtual machine is reset. This default value (120 seconds) can be changed using the advanced attribute das.iostatsInterval.
VMware DRS – Distributed Resource Scheduler:
- DRS rules can be configured to allow VMs belonging to same environment to run on the same host for better performance. For example, web server talking to a database server for the same app can be on the same host. - Using DRS, cluster can be configured for load-balancing or failover only.
VMware DPM – Distributed Power Management: DPM works with DRS to manage power in the cluster. It enables powering off underutilized hosts by moving VMs to others hosts in the cluster and placing free hosts in standby mode. Resources Pools & Shares:
- Resource Pools are hierarchical. - Resource Pools are both providers and consumers of resources. Child consumes resources from Parent pools. - Reservation: Tells ESX to power on a virtual machine only if there are enough unreserved resources. As a best practice, leave at least 10% resources unreserved. - Shares are used to set Guaranteed Reservation for VMs. - Shares are assigned values as High (4), Normal (2) and Low (1). An example of how to use these values is shown below:
- Limit: Upper bound usage for CPU and RAM Defaults to unlimited CPU (host’s maximum) and unlimited RAM (host’s maximum) Specify the limit only if you have good reasons for doing You can use the following advanced attributes to change lower bound for VPU and RAM das.vmMemoryMinMB das.vmCpuMinMHz
Storage VMotion: - Storage VMotion is the ability of vSphere to migrate VM’s storage from one datastore to another in the same cluster. During Storage VMotion a virtual machine does not change execution host. - Up to 2 migrations / host are allowed at a time.
VMware Data Recovery: Virtual Appliance based backup solution from VMware.
- Disk-based backup with de-dupe - Useful for small and medium businesses (SMBs) - Data Recover does not support using more than two backup destinations simultaneously - De-duplicated store creates a virtual full backup based on the last backup image and applies the changes to it - Data recovery backup appliance can protect a total of 100 virtual machines - iSCSI/FC SAN storage is recommended with absolute minimum of 10GB of free space, having at least 50 GB is highly recommended for typical usage. - Port 22024 must be open on ESX hosts. NOTE: DR optimizations do not apply to virtual machines created with VMware products prior to vSphere 4.0. For example, change tokens are not used with virtual machines created with Virtual Infrastructure 3.5 or earlier. As a result, virtual machines created with earlier VMware versions take longer to back up.
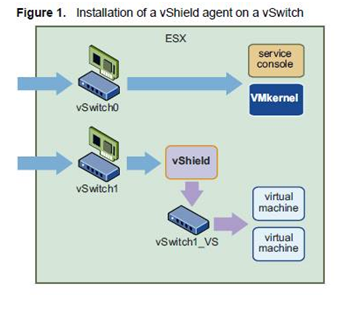
vShield Zones: An application layer firewall to protect VMs.Deployment is based on manager and agents VMs hat sits between VMs and vSwitch as shown in the diagram below.
Some of the things you should know about vShield Zones: - You will need to download vShield Manager OVF – Open Virtual Format and one vShield agent OVF templates. - VMware Wall (firewall) does application-aware traffic analysis and stateful firewall protection by inspecting network traffic and determining access based on a set of rules between unprotected and protected zones. - You can install a vShield agent on any vSwitch that homes a physical NIC. - 3 Port Groups are created namely, VSprot_vShield-name, VSmgmt_vShield-name, and VSunprot_vShield-name. - 40,000 concurrent sessions can be processed. - vShield Zone cannot protect the Service Console or VMkernel components - Works Cisco Nexus 1000V Series
Fiber Channel over Ethernet (FCoE):FCoE is the ability to make Fiber Channel Storage available over Ethernet fabrics by converting Fiber Channel commands to Ethernet commands and vice versa. vSphere has added this functionality however before you can use this feature you will need to add CNA (converged network adapter) to your server. http://www.internetworkexpert.org/2009/01/01/nexus-1000v-with-fcoe-cna-and-vmware-esx-40-deployment-diagram/ has some very detailed information about using FCoE.Here is a diagram that is a good overview of how FCoE can be setup.
Virtual Distributed Switches (vDS): vDS are new feature of VMware available only in vSphere (ESX 4) which allows the creation of virtual switches that span multiple hosts in a cluster or a across clusters in the same datacenters. This is pretty cool feature since it frees the ESX administrator from creating same vSwitch on different host multiple times in a cluster. However, this is just one the many new features that virtual distributed switch provides. Some of the others features are:
- vDS has separate control plane that is managed by vCenter - vDS has separate data plane that is managed by ESX or vSphere kernel - Ability to perform Network VMotion - Configuration is possible Individually or at the host-level - Virtual switches are abstracted into a single large vNetwork Distributed Switch that spans multiple hosts at the Datacenter level. Port Groups become Distributed Virtual Port Groups (DV Port Groups) that span multiple hosts and ensure configuration consistency for VMs and virtual ports necessary for such functions as VMotion. - dvUplink is same as a standard vSwitch. You configure NIC teaming, load balancing, and failover policies on the vDS and DV Port Groups are applied to the dvUplinks and not the vmnics on individual hosts - Private VLANs: You can configure private VLANs as follows, Promiscuous, Community, and Isolated. Communication between these private VLANs is shown in the following figure.
vApp: vApp is collection of VMs that run as a group. It is very useful if you want to run a system as one where application, database and web servers need to start and stop simultaneously.
vCenter Linked Mode: Allows connecting multiple vCenter servers together and managing all from a single vCenter server. It is not same as clustering vCenter servers.
VMSafe: A set of APIs and SDKs provided by VMware to allow third-party vendor to build security products around vSphere architecture for better performance and easy integration with VMs.
VM Hot Add Support & Hot Extend for VD (Dynamic Disks Only): Ability to add/increase resources such as vCPUs, Memory, and disk space while the VM is running. However, this greatly depends on the OS that VM is running as certain OS kernels don’t acknowledge addition of resources without a restart. Here is a nice chart that I came across while reading a blog from David Davis which is very helpful in determining whether a reboot is required or not. I am sorry I don’t have the link for the blog or name of the person who provided these results but many thanks to them for this useful information.
Also remember before you can use these features you need to upgrade VMware Hardware to version 7 and enable the support Hot Add for CPU and memory.
VMDirectPath & NPIV: Although not used by many because of many restrictions posed by these features, vSphere now allows VMs with direct access to PCI hardware devices via VMDirectPath. We can now also map LUNs directly from a VM using N-Port ID Virtualization using World Wide Names (WWNs) inside VMs. This is very useful when highly utilized VM needs to access storage directly for faster I/O. PowerCLI: Finally, the most important feature of all is the new command line tool based on PowerShell which allows administrators to perform many of the repeating and tedious tasks using PowerShell based cmdlets.
Resource Pools are both providers and consumers of resources. Child consumes resources from Parent pools.
Reservation: Tells ESX to power on a virtual machine only if there are enough unreserved resources. As a best practice, leave at least 10% resources unreserved.
Shares are used to set Guaranteed Reservation for VMs.
Shares are assigned values as High (4), Normal (2) and Low (1). An example of how to use these values is shown below:
Here is a screenshot that is very helpful in understing traffic flow and communication between deiffernt types of private VLANS (Community, Isloated, Promiscuous) in vSphere.
Ever thought, how to consolidate and utilize all that extra local storage on your VMware hosts? After all, that storage is just sitting there and can be used for storing unnecessary VMs, ISOs, templates and other non-essential stuff. One of the main issues that prevents IT managers from using local storage is its unavailability to other hosts in and across clusters. However, LeftHand's P4000 vApp for Virtual SAN Appliance solves that issue and allows other hosts in the cluster to see the local stores as iSCSI LUNs which can be mapped to each host as shared datastores.
This is very useful because for small shops that don't have the budget or need to buy expensive SAN or NAS devices can actually use this vApp to present local storage on hosts as shared storage and use high availability features like HA, DRS, Vmotion and others.
VMware Fault Tolerance or FT is a new HA solution from VMware for VMs. It is only available in vSphere 4 and above and provides much more resilient failover solution than VMware HA. One of the nice things about FT is that a VM does not need to be restarted. However, before you can start using FT for your important VMs like Domain Controllers and others here is what you need to know about Fault Tolerance?
Similar to VMware HA, Fault Tolerance (FT) provides failover capabilities at the host level failure. So it will fail over VMs only when host in the cluster fails. It does not work across clusters or datacenters.
FT uses vLockstep technology. vLockstep technology is the process of recording and replaying x86 instructions from Primary copy of the VM to Secondary VM. vLockstep also keeps track of the heartbeat between primary and secondary VMs.
While vCenter or virtual center is required to configure FT. It doesn’t have to be ON during a failure event.
You can have On-Demand Fault Tolerance for a VM.
FT makes sure that both primary and secondary VMs are on the same host using host anti-affinity check.
Following requirements must be met for VMs before FT can be configured:
Host must have certificate checking enabled
FT is enabled per VM
vmdks must be thick provisioned
All hosts must be from the same compatible process groups which support FT
No Snapshots: A VM participating in FT cannot have any snapshots
No Storage VMotion: A VM participating in FT cannot use Storage VMotion
No DRS: A VM participating in FT cannot use DRS
No SMP: A VM in FT can only have single vCPU
No RDMs: A VM in FT cannot have RDMs but it can have vRDMs
Hot-add/hot-plug is not compatible with VMware Fault Tolerance
Upon a host failure a new Secondary VM is automatically re-spawned
VMware HA must be on turned on in the cluster before FT can be enabled
Host Monitoring in VMware HA is required for FT recovery process to work properly.
FT Networking: You must have 2 different vSwitches, one for FT Logging and second for VMotion on different subnets or VLANs. It’s recommended to use 10Gb network for FT Logging traffic along with Jumbo Frames.
FT Maximums: You should not have more than 4 FT VMs per host which includes both Primary and Secondary VMs. A max of 16 vmdks per VM is allowed.
If you are a full-time E-mail administrator then this information is going to be very helpful for you but it is also very useful for those managing any email domain.
MX Toolbox is great site with many tools for E-mail monitoring and recenly they have included many new tools.
You can register to monitor your domain for blacklist monitoring for FREE. This is very useful if you want to be alerted right away when your domain ends up on an RBL. They monitor over 150 blacklists and alert you via email whenever your domain is spotted on a blacklist.
Here is screenshot from vSphere Admin guide on HA. I also have included sample cluster HA information to show that without Admission Control Policy default HA settings do not guarantee failover of all VMs even when one thinks that all hosts have are running more VMs than slots available.
HA is the ability of VMware to power on VMs on another ESX host in case one or more hosts fail in a cluster. Some of the things that you need to know about VMware HA are:
HA Calculations: HA is based on what is called a “slot”. A slot is basically a reserved space for running a VM in the cluster. Two features that determine a slot are CPU and RAM used by VM. By default VMware HA selects the slot size to be the largest chunk of CPU and RAM used by a VM as shown in the diagram below. HA uses this to determine the number of slots available in the cluster to run the VMs in an HA event. The default selection can be changed by modifying the following advanced attributes:
das.slotMemInMB – Change the memory usage by a VM for slot calculations
das.slotCpuInMHz – Change CPU usage by a VM for slot calculations
First 5 hosts in a cluster are designated as Primary for HA. At least 1 node in the cluster is selected as Active Primary.
HA agent is installed on the ESX host and polls for heartbeat every second by default.
Failure is detected if no heartbeat is received in 15-seconds
Isolation Network is polled every 12 seconds after which host is designated as Isolated. Service Console default gateway for ESX and VMkernel default gateway for ESXi are pinged for detecting isolation. You can also designate other addresses by modifying das.isolationaddress include other destination in the detection process.
Admission Control Policy: Ability to reserve resources for HA. You can use Host, VM Restart Priority to control admission policy. VM Restart priorities are defined as
High – First to start. Use for database servers that will provide data for applications.
Medium – Start second. Application servers that consume data in the database and provide results on web pages.
Low – Start Last Web servers that receive user requests, pass queries to application servers, and return results to users.
Disables admission control: If you select this option, virtual machines can, for
example, be powered on even if that causes insufficient failover capacity. When
this is done, no warnings are presented, and the cluster does not turn red. If a cluster has insufficient failover capacity, VMware HA can still perform
failovers and it uses the VM Restart Priority setting to determine which virtual
machines to power on first.
Enable port fast (Cisco) on the switches as best practice for bypassing spanning tree delays.
VM Monitoring – HA also has the ability to monitor VMs but requires that VMware Tools be installed and running. Occasionally, virtual machines that are still functioning properly stop sending heartbeats. To avoid unnecessarily resetting such virtual machines, the VM Monitoring service also monitors a virtual machine's I/O activity. If no heartbeats are received within the failure interval, the I/O stats interval (a cluster-level attribute) is checked. The I/O stats interval determines if any disk or network activity has occurred for the virtual machine during the previous two minutes (120 seconds). If not, the virtual machine is reset. This default value (120 seconds) can be changed using the advanced attribute das.iostatsInterval.
Here are two great sites that you can use for finding information on number of features like SMTP, Blacklist monitoring, Open-Relay tests, Test-email, etc.
You can remove the OS option from Windows 7 boot loader screen by using the following commands in CLI:
bcdedit /bootsequence {current} /remove
bcdedit /displayorder {current} /remove
where {current} is the name of the OS you want remove from boot loader.
VMware Site Survey is a very useful utiltiy from VMware that allows you to test whether or not your VMwar environment is ready to use new VMware features such as Fault Tolerance. You can download the utiltiy from VMware website. It runs from your desktop and connects to vCenter. At the end you are presented with an HTML report which explains the results and why certain component is not compatible with new feature(s). It also provide links to HCL for certain hardware.
SAN maintenance is an integral part of and IT manager. However, many of us can't remember some of the easy steps that are required to perform some low level SAN maintenance tasks since we don't perform these tasks very often. Here are quick steps of how to remove a storage group after host(s) are decommissioned and no longer needs the storage.
1. Connect to Navisphere 2. Expand to Storage Group branch in the Local Domain tree 3. Select the storage group you want to remove and right click
4. Select Connect Hosts from the list
5. Select host from the left and click the left arrow to move the host to available hosts on the left.
6. Go to LUNs tab and select the LUNs at the bottom in the Selected LUNs
7. Click Remove
8. Click Apply and Ok
9. Right the click the storage group in question and select Destroy from the list
10. Confirm and close navisphere.
Note: The LUN(s) are still there. You can remove them by going to LUN folder branch and unbind them.
How to multihome a Windows server using Microsoft Software iSCSI Initiator to an iSCSI SAN?
This post focuses on connecting a Windows 2008 physical server to EMC CLARiiON CX3-10c using two NICs and Microsoft Software iSCSI initiator. However, this information can also be used for connecting any Windows 2003 server and iSCSI SAN.
Step 1. Connect to Navisphere using your Java enabled browser and Identify iSCSI traffic subnet for the iSCSI ports. You will need single available IP address from each subnet to assign to each of the NICs in the server. You should rename the NICs iSCSI#1 and iSCSI#2.
Step 2. Open iSCSI initiator and go to Discovery tab then click Add Target Portal and enter either of the IP address listed on the target in the figure above in Step 1. Enter 3260 for port. Hit Ok.
Step 3.Go to Targets tab and notice that all targets are showing up as Inactive. This is normal.
Step 4. Go back to Navisphere and right click the array serial number under Local Domain and select Connectivity Status from the list, Click Group Edit button, and highlight and select the Windows hosts' Initiators WWN which start with iqn.xxx.xxx from the Available WWN from left box show. Hit the right arrow button to move these to Selected WWN strings as shown in the figure below.
Step 5.Now to go back to Windows Host and open Software iSCSI Initiator properties dialog box.
- Select the first inactive target and click on Log on ... button
- Tick both checkboxes for Automatically restore... and Enable multi-path...
- Click on Advanced button and select Micrsoft iSCSI Initiator for Local adapter Source IP for first NIC (iSCSI#1) and Target Portal on the same subnet as the Source IP
- Click OK buttons all the way back to the Targets tab on the properties box of iSCSI initiator- Repeat these steps for all inactive targets until you see all targets connected. Remeber to use the same subnet for each source IP.
Step 6. Choose a load balance policy for iSCSI connection i.e. Round Robin, Failover, etc. Failover is fine for this example.
Step 7.Enable MPIO. Go to Discover Multi-paths and select Add Support for iSCSI devices. Reboot the machine.
Step 8.Create new RAID groups or use existing ones to create new LUN(s). Create a new storage group for the host and add the LUNs to the storage group. Connect the Host to the storage group from the available connections lists. Reboot the host one more time.
Step 9.Go to disk management tool using diskmgmt.msc and format the disk and assign the letter.
Step10. Perform failover test by disabling iSCSI#1 NIC and then disabling iSCSI#2 NIC.
VMware vSphere or VI3 doesn't provide a native way to run scheduled snapshot reports. However, having a dailysnapshot report can be very useful specially if you are using an snapshot based backup software to backup yourVMs like Vizioncore's vRanger Pro. Orphaned or uncleaned snapshots can be problematic because they grow in size and can fill up space on the datastore where snapshot is residing. These lingering snapshots can cause VMs to become corrupt or other new backup jobs from completing.
For VI3 you can write a perl script that runs on each ESX host. However, now VMware provides a scripting mechanism based on PowerShell called PowerCLI which has over 140 cmdlets used by VMware admins to manage vSphere and VI3 (3.5 Update 2 and above) environment.
I couldn't find any script online that would provide this functionality so I wrote a PowerShell script using PowerCLI myself and here it is.
1. Download the zip file to local vCenter server and extract to a folder. There are three files .ps1, .bat and .xml.
2. Modify the script configuration section to include your company's information For example # Configuration Parameters: Update your information here. # ------------------------------------------------------- $server = "vcenter.abc.com"
$user = "abc\admin-vc" $pass = "ABCPassword"
$SMTPserver = "smtp.abc.com"
$from = "vcenter@abc.com"
$to = "alerts@abc.com"# ------------------------------------------------------- 3. Install PowerShell and PowerCLI on vCenter server
4. Enable remote script execution by running Set-ExecutionPolicy RemotelySigned
5. Schedule the script in Windows Scheduler using the batch file provided.Full Script #
# Created 3/5/2010
#
#
# Purpose: Creates and email snapshot report in html format for all VMs running on VMWare vSphere
#
# Usage Notice: Use at your own risk
#
# Configuration Parameters: Update your information here.
# -------------------------------------------------------------
$server = "vcenter.yourdomain.org"
$user = "Windows-UPN\admin-user"
$pass = "Password"
Using Recovery Storage Group to restore mailbox items or complete mailboxes can be quite difficult for someone new to Exchange 2007 interface. RSG was introduced in Exchange 2003. It allows the mounting of production and backup databases side by side and uses built-in ExMerge in Exchange 2007 Tools to do the merge.
Here are detailed guidelines that you can download with screenshots and instructions on how to perform a restore from backup tapes using Symantec BackupExec and Exchange 2007 SP1 Recovery Storage Group. Note: You can only have on RSG at a time.
Summary Step 1 Open EMC on either active or passive nodes and go to Toolbox. Double click Database Recovery Management Step 2 Get the latest updates if updates are available. If not, click Go to Welcome screen Step 3 Enter the server name (CCR Node) and click Next Step 4 Click Create a recovery Storage Group Step 5 Click Storage Group that you want to restore (i.e. S07) and click Next
Step 5a Create a folder with the same name as shown for Recovery storage group (R00.log) log path (i.e. RSG20090828163917) under S07-LOGS subdirectory. Step 5b Now click Browse for Recovery Storage Group (R00.chk) path and select the folder you created in the previous step. Step 5c Click Create Recovery Storage Group Step 6 Once storage group is created, click Go back to task center Step 7a Now Login to the backup (media) server. Open Backup Exec GUI Step 7b Create a Restore Job with settings shown in the following 3 screenshots and click submit. Wait for the job to finish restoring. The time it takes to restore will depend on weather you’re restoring from disk or tape. In this example we are restoring from disk. Step 8 Go back to EMC and click on Mount or dismount databases in the recovery storage group Step 9 Once completed click on Go back to task center Step 10 Click on Merge or copy mailbox contents and follow the steps in the next 7 screenshots Step 11 Once completed, click Go back to task center Step 12 Click on Mount or dismount databases in the recovery storage group to dismount the database the recovery database. Follow the step in the next 4 screenshots
Congratulation! You have successfully restored a mailbox using Exchange 2007 Recovery Storage Group and embedded ExMerge.
You can now close EMC.